


Domain-Driven Serverless Design
One reason I really like the serverless architecture approach is being pretty selfish: one has to care only about what matters - the code.
Well, I know code is not everything, but as a developer, I'm just having more fun coding than scripting infrastructure in YAML or similar. For people like me is the serverless model a dream come true. But how to do serverless without turning the dream into a nightmare?
It's well known that the microservices-first approach leads often to a failure. The point here is to know the domain well before splitting the system up into autonomous services. Once split up refactoring across boundaries becomes difficult (or even impossible) due to the lack of collective code ownership. Werner Vogels' famous statement says "APIs are forever", once published the interface cannot be changed. Without knowing the domain well one usually ends up with a CRUD-like entity services, which wakes him up every night in a lather of sweat.
Let's illustrate this with an example. A CRUD-like entity service looks like this:
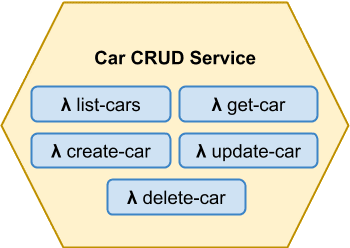
We have here one (micro)service built around the Car entity and five functions (some people call them nanoservices) implementing its CRUD operations. The potential database or a storage is an internal part of the service and it's not accessible or visible to the outer world.
Consider a car rental company with a web page displaying a list of cars available to rent. With only entity services the page controller must retrieve a list of all cars from the Cart service, then a list of all rentals from the Rental service and finally match cars not included in any rentals:
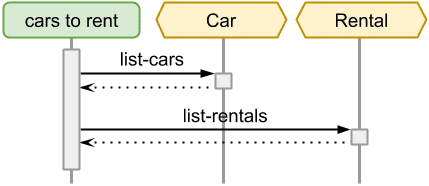
Even in this simple scenario there are several problems:
- Knowledge of Car and Rental entities on the client side leads to tight-coupling of the services.
- Availability of the feature relies on all involved services.
- Multiple synchronous requests result to a lot of overhead and increase costs rapidly.
- Transferring more data really needed means throughput waste.
- Complex communication makes the system difficult to reason about.
One can easily image a more complex scenario where a function calls a function which call a function... This ends up not only in mess but in a very expensive mess, as synchronous calls in functions are charged for both the blocked caller and the blocking callee.
Synchronization always means coupling. Serverless systems are great for an asynchronous communication, which is however not always possible. Fortunately, there are several options how to tame this beast. Using tools like AWS Step Functions or Azure Logic Apps can optimize the composition of function calls, but it's still not applicable everywhere. The solution is to design the services in a way they don't need to make any synchronous calls whatsoever - make them domain-driven!
How would the scenario be implemented in the domain-driven style? Well, what is the feature here? The controller method already told us: cars to rent.
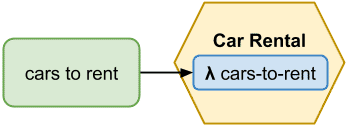
Now, the controller makes only one single request to get a list of cars available to rent, exactly what asked for. Further there will be function like rent-a-car, return-a-car or extend-a-rental. All of those are autonomous, which means, they have all they need to work the feature out. Again, the service contains its own data, gathered for example by an event listening function like a-new-car-stored and similar.
Important to notice is the names of new functions - all are domain-driven. Technical concepts like create or delete disappeared from the model completely and that's the whole point.
To summarize it:
- Know your domain well,
- build services around the domain,
- sleep well in the night.
Before we reach the first point, we should forget not only about serverless but microservices as well. First, a monolith is the right way to go. Growing up enough to know the domain boundaries well, we can start with big services. Splitting them up into serverless functions is the last step.