


OPC UA Basic Concepts
Elemental terms and core concepts of OPC UA with all of the important details crunched for beginners and intermediate practitioners.
The OPC UA specification is divided into more than twenty parts and has thousands of pages. It is not easy to separate fundamentals from mere details when getting started.
This post will provide a brief overview of the basics that are necessary to understand when developing OPC UA solutions. We will focus on the very essential: communication and data modeling.
Motivation
What is OPC UA anyway and why should we care?
OPC UA (Open Platform Communications Unified Architecture) is an open industry standard defining an interface and modeling system for machine-to-machine communication. It is mainly used in industrial automation for standardized read-and-write access to current and historical data.
OPC UA uses the client-server approach, where the server typically encapsulates the device data and makes it available to the client via a well-defined interface. An OPC UA application can be both server and client to enable machine-to-machine communication.
Data modeling in OPC UA uses object-oriented techniques including type hierarchies and inheritance to describe systems of arbitrary complexity. The data structure of an OPC UA server is self-descriptive and enables the client to navigate through instances and types with little to no prior knowledge.
OPC UA describes platform and vendor-independent service-oriented architecture. The complete software stack can be implemented with C/C++, .NET, Java, or JavaScript. OPC UA is not limited to these programming languages and development platforms.
OPC UA specifies data encoding, security, and transportation with the focus on reliability, robustness, scalability, interoperability, and high performance in communication between distributed systems.
OPC UA is extended by a bunch of companion specifications for specific purposes (e.g. commercial kitchen equipment).
OPC UA is maintained by the nonprofit OPC Foundation.
History
OPC UA is a unification of three older OPC Classic specifications: Data Access (DA), Alarm & Events (A&E), and Historical Data Access (HDA) into one extensible framework.
DA describes access to current data, A&E describes an interface for event-based information, including acknowledgment of process alarms, and HDA describes functions used to access archived historical data.
OPC Data Access was released in 1996 as a specification for device drivers providing standardized access to automation data.
The OPC Unified Architecture (UA), released in 2008, was designed to enhance and surpass the capabilities of the OPC Classic specifications. OPC UA is functionally equivalent to OPC Classic, but provides more powerful possibilities exposing the semantics of the data, discovery of servers on networks, subscriptions on data changes, notifications, and method executions.
Encoding, Security and Transportation
Technology mappings address three tasks which are necessary for exchanging data between OPC UA applications: data encoding, securing the communication, and transporting the data.
A combination of these three technology choices is called a stack. The mappings are organized into three groups: data encodings, security protocols, and transport protocols. Different mappings are combined to create stack profiles. All OPC UA applications should implement at least one stack profile and can only communicate with other OPC UA applications that implement the same stack profile.
![]()
Each stack profile should be treated as a single Layer 7 protocol that is built on an existing Layer 5, 6 or 7 protocol such as TCP/IP, TLS, or HTTP.
Data encoding
Data encoding is the serialization of the messages including their input and output parameters to a network format. OPC UA currently specifies three encodings: OPC UA Binary, OPC UA XML, and OPC UA JSON.
OPC UA Binary is the most efficient encoding with less overhead over the wire and therefore the one that is most used. Every OPC UA application must support this encoding.
OPC UA XML is designed to exchange data in a format that can easily be consumed by different applications and platforms as well as by humans.
OPC UA JSON is meant to be used in JavaScript-based applications that run directly in the web browser.
A further aspect that is common for all encoding types is the extension object. This is a special type of container for any complex data independent of the encoding. In addition to the encoded data, it also contains an identifier which indicates how it is encoded.
Security Policies and Profiles
OPC UA supports the selection of several security modes: None, Sign, and SignAndEncrypt.
If None is used, the messages will not be secured. When Sign is chosen the messages are signed with the associated private key of the client certificate. Signing messages allows for detecting whether a received message has been manipulated by an untrusted third party. If SignAndEncrypt is used, messages are additionally encrypted with the public key of the server certificate.
A security policy specifies which security mechanisms are to be used. Security policies are used by the server to announce which mechanisms it supports and by the client to select the one it wishes to use for the communication. Security policies are also used with pub-sub communication.
Two OPC UA applications can only communicate with each other if they have at least one security policy in common. However, applications can be configured to not accept certain security policies although they support them (from the implementation point of view).
The choice of which security function is used for a connection is carried out by agreeing on a specific security policy between the client and server in advance. It is identified by a well-defined URI and contains unique names of security algorithms for different purposes such as signing and encrypting. For example, http://opcfoundation.org/UA/SecurityPolicy#Basic128Rsa15 is a security policy defining the AES algorithm with 128 bits keys for encrypting and signing messages symmetrically and the RSA 1.5 algorithm for asymmetric operations.
Connection establishment
The connection establishment between an OPC UA client and an OPC UA server requires the creation of a secure channel and a session.
A secure channel is the low-level and protocol-dependent channel used to secure the communication and the exchanged messages. This level is handled completely by the OPC UA stacks hiding the different possible protocols. The secure channel layer is always present even if the security mode is None.
A session is the connection context between the two applications. The lifetime of the session is independent of the secure channel and another secure channel can be assigned to the session. A session has a timeout that allows the server to free the resources after a defined time period.
Once a session is already activated a further request to activate the session could be used with credentials of a different user to change the owner of the session.
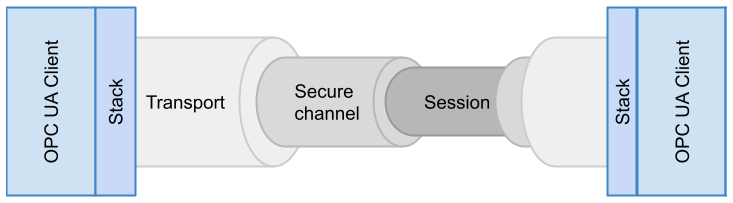
Establishing a new connection has four steps:
- The client informs itself about the different configuration options of how the connection to the server can be established. As soon as the client receives a response, it selects an endpoint with special security settings it can handle and validates the server certificate.
- The client sends a request to open a secure channel. The server responds with a secure channel according to the selected security mode and policy.
- The client sends a request to create a session in addition to the previously established secure channel.
- Before the created session can be used by the client and the server it must be activated. The client sends a request to activate the session to the server including the credentials of the current user together with the client certificate.
Authentication and Authorization
OPC UA uses a concept conveying application authentication to allow applications that intend to communicate in order to identify each other.
Each OPC UA application instance (client or server) has an assigned certificate that is exchanged during the secure channel establishment. The receiver checks whether it trusts the certificate and accepts or rejects it by sending a corresponding response to the sender.
HTTPS can also be used to create secure channels; however, these channels do not provide any application authentication.
User authentication and authorization means that an OPC UA server can verify that the user intending to access data of the server is really the user he claims to be. User authentication is achieved when the client passes a user identity token to the server via a session.
OPC UA applications accept user identity tokens in any of the following forms: username/password, X.509 certificate, or JSON Web Token (JWT).
OPC UA applications may determine in their own way what data is accessible and what operations are authorized or they may use the concept of roles.
Transport Protocols
OPC UA specifies an abstract protocol that establishes a full duplex channel between a client and server. Concrete implementations include OPC UA TCP, OPC UA HTTPS, and WebSockets.
OPC UA TCP is the default implementation based on TCP/IP. The URL scheme for endpoints is opc.tcp.
When using OPC UA HTTPS, all communications via a URL shall be treated as a single secure channel that is shared by multiple clients. Client certificates are allowed, but not required.
WebSockets is a bi-directional protocol for communication via a web server which is commonly used by browser-based applications to allow the web server to asynchronously send information to the client. WebSockets uses the same default port as HTTP or HTTPS and initiates communication with an HTTP request. A server that supports the WebSockets transport publishes endpoints with the scheme opc.wss.
Data Modeling
The data modeling defines the rules and base building blocks necessary to expose an information model with OPC UA. It also specifies the entry points into the address space and base types used to build a type hierarchy. This base can be extended by information models building on top of abstract modeling concepts.
OPC UA data modeling uses object-oriented techniques including type hierarchies and inheritance. Typed instances allow clients to handle all instances of the same type in the same way. Type hierarchies allow clients to work with base types and ignore more specialized information.
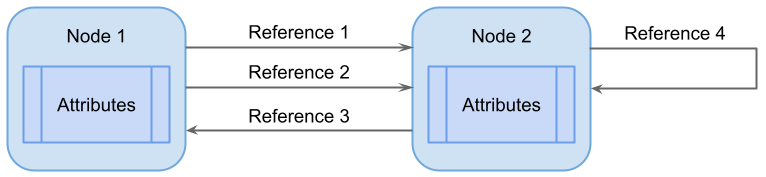
The base modeling concepts of OPC UA are nodes with attributes and references between nodes.
Information Model
The OPC UA address space defines the meta-model of OPC UA. The base information model builds the foundation for creating standard or vendor-specific information models tailored for specific domains.
Address space defines node classes, base types, and constraints. An information model uses the concepts of the address space to define its own domain-specific types and constraints as well as well-defined instances. Finally, the concrete data of a server is created based on the information model.
The base information model provides a framework for all information models using OPC UA:
- entry points into the address space used by clients to navigate through the instances and types of an OPC UA server,
- base types to build the root for the different type hierarchies,
- built-in but extensible types like object types and data types,
Serverobject providing capability and diagnostic information.
Other organizations can build their models on top of the UA base or on top of the base information model, exposing their specific information via OPC UA. A vendor will use the base model and extend it with vendor-specific information about his devices.
Information models are specified by XML documents based on a specific XML schema and can be used for code generation. Typically, a server will support several information models where some may be based on other information models.
Nodes
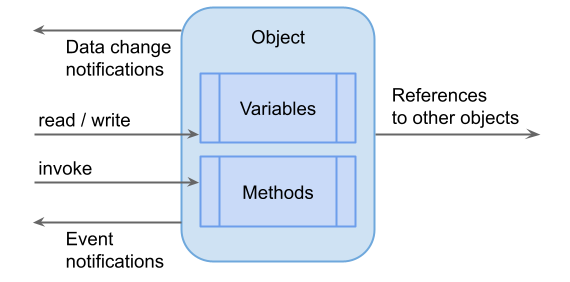
Nodes can be of different node classes, depending on their purpose. There are nodes representing instances, others representing types, etc. The base node classes are objects used to structure the address space and to provide events, variables containing data in its value attribute, and methods that can be executed in the server.
A node class is an enumeration of values Object, Variable, Method, ObjectType, VariableType, ReferenceType, DataType, and View.
Attributes
Attributes are used to describe nodes, and depending on the node class a node can have a different set of attributes. Each node class has a fixed set of attributes, whereas references do not have attributes.
Clients can access attribute values using read, write, or query services. Attribute definitions are included as part of the node class definitions and, therefore, are not included in the address space.
The attributes of a node depend on its node class. However, there are some attributes common to every node:
| Attribute | Data type | Description |
|---|---|---|
NodeId | NodeId | Uniquely identifies a node in the server and is used to address the node in the services |
NodeClass | NodeClass | An enumeration identifying the class of a node |
BrowseName | QualifiedName | Identifies the node when browsing the server. It is not localized |
DisplayName | LocalizedText | Contains the name of the node that should be used to display the name in a user interface. Therefore, it is localized |
Description | LocalizedText | Optionally provides a localized textual server-specific description of the node |
WriteMask | AttributeWriteMask (subtype of UInt32) | Optionally specifies which attributes of the node are writable, i.e., can be modified by the client |
UserWriteMask | AttributeWriteMask (subtype of UInt32) | The same as WriteMask but of the current session. |
AccessRestrictions | AccessRestrictionType (subtype of UInt16) | Optionally specifies server-specific restrictions on the client to access the node |
See the summary of attributes of the node classes.
References
A reference describes the relation between precisely two nodes. Like attributes, references are defined as fundamental components of nodes. Unlike attributes, references are defined as instances of ReferenceType nodes.
Objects
Objects have variables and methods, can fire events, and can be used to group other objects. Methods and variables always belong to an object.
Objects support type hierarchies and inheritance.
An object can be an event notifier. Clients can subscribe to an event notifier to receive events.
To promote the interoperability of clients and servers, the OPC UA address space is structured as a hierarchy, with the top levels standardized for all servers. Servers typically implement a subset of these standard nodes, depending on their capabilities:
Views- the browse entry point for views. Only organizes references.Types- the browse entry point for type nodes.Objects- the browse entry point for object nodes.Objects/Server- the browse entry point for information about the server.
Variables
A variable represents a value. Clients can read and write its value and subscribe to changes of the value.
Two types of variables are defined: properties and data variables.
Properties are used to represent the characteristics of an object, for example, containing the engineering unit of a measured temperature (e.g.: °C, °F). Their values are simple and do not change very often.
Data variables represent the data of an object, like the temperature of a temperature sensor, and have sub-variables containing parts of the data and properties describing them.
Variables have some additional common attributes:
| Attribute | Data type | Description |
|---|---|---|
Value | Defined by the DataType attribute | The actual value of the variable |
DataType | NodeId | This attribute contains a node ID of such a node defining the data type of the value |
ValueRank | Int32 | Identifies if the value is an array |
ArrayDimensions | UInt32[] | This optional attribute allows specifying the size of an array |
AccessLevel | AccessLevelType (subtype of Byte) | Indicates whether the current value is readable and writable as well as whether the history of the value is readable and changeable |
UserAccessLevel | AccessLevelType (subtype of Byte) | Same as AccessLevel but takes user access rights into account |
MinimumSamplingInterval | Duration (subtype of Double) | Provides the information how fast the server can detect changes of the value (used for polling) |
Historizing | Boolean | Indicates whether the server currently collects history for the value |
AccessLevelEx | AccessLevelExType (subtype of UInt32) | Extended version of AccessLevel for information about its atomicity |
Methods
A method represents an executable operation, that is, something that is called by a client and returns a result. Each method specifies the input and output arguments.
There are additional attributes and standard properties for methods:
| Attribute | Data type | Description |
|---|---|---|
Executable | Boolean | A flag indicating if the method can be invoked at the moment |
UserExecutable | Boolean | Same as Executable taking user access rights into account |
InputArguments | Argument[] | This optional property defines an array of input arguments for the method |
OutputArguments | Argument[] | Same as InputArguments for the output of a method |
Namespaces
OPC UA servers can support several information models simultaneously. Each organization uses its own namespace URI (which, by definition, is unique). This allows servers to expose several information models without name conflicts.
Every information model must have its own unique identification URI. For the base OPC UA specification, this URI is http://opcfoundation.org/UA/. Additional companion specifications or custom specifications define their own namespace URI, e.g., http://opcfoundation.org/UA/DI/ for the DI specification.
Inside an OPC UA server, the namespace is identified by a namespace index. Index 0 is always the base model, and index 1 relates to any instances of nodes which do not belong to a specific model. A server can load additional models into its address space; these normally start at index 2.
Node ID
A node ID uniquely identifies a node inside its model. The node ID always consists of two parts: the namespace index, and the identifier. Every information model defines the node ID for all nodes defined inside that model.
The server returns node IDs when browsing or querying the address space and clients use the node ID to address nodes in the service calls.
The identifier can be a numeric value, a GUID, a string, or an opaque value (byte string). Those most commonly used are the numeric and string node IDs.
A node ID and namespace index combination is only valid for this specific server instance because the namespace index may change during different server instances.
A node can have several alternative node IDs that can be used to address the node. The canonical node ID can be gained by reading the NodeId attribute, even if the node was accessed by an alternative node ID.
Type Definitions
OPC UA servers provide type definitions for objects and variables. The HasTypeDefinition reference is used to link an instance with its type definition represented by a TypeDefinitionNode. Objects and variables inherit the attributes specified by their TypeDefinitionNode.
Type definitions are required; however, the base information model defines the BaseObjectType, PropertyType, and BaseDataVariableType so a server can use such a base type if no more specialized type information is available.
Subtyping of type definitions is allowed.
Data Types
Data types are used to describe the structure of the value attribute of variables and their variable types.
Data types are represented as nodes in the address space. Each variable is pointing with its DataType attribute to a node of the DataType node class.
OPC UA distinguishes four kinds of data types:
- Built-in data types: a fixed set defined by the OPC UA specification that can be extended by standardized or vendor-specific information models. They provide base types like
Int32,Boolean,Double, and also OPC UA specific types likeNodeId,LocalizedText, andQualifiedName. - Simple data types: subtypes of the built-in data types. They are handled on the wire exactly like their supertypes, that is, a concrete value of a simple data type cannot be distinguished from the same value of its supertype when sent by the server and received by a client or vice versa. An example is
Durationas a subtype of Double defining an interval of time in milliseconds. - Enumeration data types: a discrete set of named values. Enumerations are always handled the same way as the built-in
Int32data type on the wire. An example isNodeClass. - Structured data types: user-defined, complex data types for structured data. An example is
Argumentused to define an argument of a method.
In addition to those data types, there is a set of abstract data types that do not fit into these categories and are only used to organize the data type hierarchy.
Modeling Rules
A modeling rule specifies what happens to an instance (object or variable) of a type definition containing the modeling rule.
There are three fundamental choices, also called the naming rule of the modeling rule:
- Mandatory: each instance must have a counterpart of the declaration.
- Optional: each instance may have such a counterpart, but it is not required.
- Constraint: defines a constraint for instances; for example a cardinality restriction.
Views
Views can be used to organize an address space for different tasks, providing only the needed information for the specific task. They are used to restrict the number of visible nodes and references in a large address space to tailor it to specific use cases.
A view is a node that gives an entry point into the content of the view.
The node ID of the view node can be used as a filter parameter when browsing the address space.
Historical Data
OPC UA allows accessing and changing the history of the value attribute of a variable.
The AccessLevel and the UserAccessLevel attributes indicate whether the history is accessible and changeable, the first one in general and the second one taking the access rights of the current user into account. These attributes indicate whether some history is available, but not if the history is currently collected. Therefore, the Historizing attribute is used, indicating whether or not the history is currently collected.
OPC UA only allows historizing the value attributes of variables. If a server collects the history of other attributes and wants to expose that and make it accessible, the most appropriate way is to create a property for each historized attribute and add those historized attributes to the node.
The history of events can be gained from event notifiers, that is, objects and views. The EventNotifier attribute indicates whether the history of events can be accessed and manipulated.
Besides dealing with the history of current data and events, nodes and references may be added or deleted over time. OPC UA allows clients to track such changes and to access different versions of the address space by referencing different points in time. A server can achieve this by supporting a versioning of nodes and special events for changes of the model. To access different versions of the address space, a certain version or a certain point of time can be provided while browsing and querying the address space.
Profiles
Not every OPC UA application will support all the functionality of OPC UA. For example, a server running on an embedded device may not provide any historical information or may not even be able to support subscriptions. To handle OPC UA applications with different functionalities, OPC UA introduces profiles.
Profiles describe useful subsets of OPC UA features. They define the functionality of an OPC UA application. Profiles in general contain functionality that an application must support in order to be compliant.
An OPC UA application can support several profiles and each profile can contain other profiles. Profiles have different categories: server-, client-, security-, or transport-related.
Server-related profiles can be facets or full-featured. Full-featured profiles define a set of testable units that are expected to be supported by many applications. An OPC UA server needs to support at least one full-featured profile. Facets define certain capabilities of the server such as supporting event subscriptions. Additional facets can be added to a server, extending the functionality supplied by it.
The decision of which profile to choose for your application depends on the needs of the clients. At least an OPC UA server should implement the Standard 2017 UA Server Profile which includes the UA-TCP UA-SC UA-Binary facet.
Services
OPC UA services define the data communication on the application level. They are the communication interface between servers as suppliers of an information model and clients as consumers of that information model.
The services are defined in an abstract manner. The definition of the services is independent of the transport protocol and the programming environment.
OPC UA services come in two types: one creates a communication context such as the secure channel and session and the other exchanges information such as browsing, reading, writing, and calling methods.
The services use the request-response pattern. Upon receipt of the request, the server processes a message in two steps: first, it decodes the message and locates the service to execute, then it attempts to access each operation identified in the request and perform the requested operation.
For each operation in the request, the service provides a timestamp and quality in the response. The quality specifies if the data is accurate (good), not available (bad), or unknown (uncertain).
Some important services are
- Discovery service: used by clients to find available OPC UA servers and to acquire information about the available endpoints of registered servers.
- Browse service: used by a client to navigate through the address space by passing a starting node and browse filters.
- Read service: used to read one or more attributes of one or more nodes.
- Call Service: used to actually call a method.
- Node management service: used to add, modify and delete nodes in the address space.
Implementation
The following layers with certain responsibilities are defined: application layer, SDK layer, and stack layer.
The stack layer is responsible for the lower-level functions such as encoding and decoding messages, securing messages, as well as sending and receiving messages. It has an additional layer containing only platform-specific code whereas the other layers are written in a platform-neutral manner. This facilitates the portability of the stack to other platforms.
The SDK layer contains higher-level functionality covering OPC UA-specific functions such as OPC UA services and common capabilities such as configurations and logging.
The application layer covers the use-case-specific part of the functionality.