


Use-Case-Driven Testing
Why shouldn't we test the implementation? How to decouple our tests from the code? What is the reason to add a new test? Why is mocking a code smell? In this article I will try to find answers to those questions.
In my previous article I opened the topic and defined some important terms and principles I find good to follow. Let me summarize some of them and continue in the theory how we should design our tests.
Contracts Testing vs. Implementation Testing
We can see a test as a friend of our application but never as its part (tests codebase is never a part of the production application). As a good friend a test must talk to the application via a contract. We can call that contract an API. Every well-defined component offers an API.
If we couple our test with the implementation, we have to adapt the test everytime we refactor the application code, which is not only annoying and impractical but unnecessary and even rude (we don't snoop around in friend's wardrobe). After some time people get sick of double work and start to write fewer tests and/or ignore broken tests.
Tests should not care how is a feature implemented, they should care only if the behavior is correct. When we implement a sorting function we should test if the sorting results are correct regardless which sorting algoritm is used.
For example when we test if a record was saved we can use another service to retrieve the record, again via its API. When there is no API to retrieve a record there is no possibility to validate if the record was really save - but such a "black hole" system makes no sense.
Code-Drive Testing vs. Use-Case-Driven Testing
It's a very popular practice to have a test per class, in Java like following:
/src/main/java/Foo.java
/Bar.java
/src/test/java/FooTest.java
/BarTest.java
This is a typical example of code-driven testing design. Here is a new class a reason to add a new test. But a class is just an implementation detail. Maybe after some time you find out the class is too big and should be refactored into two classes. Then you have to refactor your test as well although there is no functional change and the test validates always the same behavior. But if you didn't do it your test wouldn't propably compile. An unhappy situation. Code-driven testing design makes maintenance hard, expensive and boring.
It is much better to drive your tests by use-cases. With this strategy not a class or a method is a reason to add a new test but a new requirement is. The structure looks like following:
/src/main/java/Foo.java
/Bar.java
/src/test/java/UseCase1Test.java
/UseCase2Test.java
When you decided to split a class into two or to remove one, the tests remain without any change:
/src/main/java/Foo1.java
/Foo2.java
/src/test/java/UseCase1Test.java
/UseCase2Test.java
In fact, there are only two reasons for a test change: 1. the requirement has changed, 2. there was a bug in the test self.
The design of the test has the following pattern:
class UseCaseTest {
@Test
public void requirementOneTest() {
assert(/* acceptance criterium 1 */);
assert(/* acceptance criterium 2 */);
...
}
@Test
public void requirementTwoTest() {
assert(/* acceptance criterium 1 */);
assert(/* acceptance criterium 2 */);
...
}
...
}
The API is defined by an inteface (each public method of a class should implement an interface) and the implementation should be initialized via a factory, for example:
/** src/main/java/MyUseCase.java */
public interface MyUseCase {
int func1(String param);
String func2(int param);
}
/** src/main/java/Foo.java */
class Foo implement MyUseCase {
private Bar bar = new Bar();
public int func1(String param) {
...
}
public String func2(int param) {
...
return bar.func();
}
}
/** src/main/java/Bar.java */
class Bar {
String func(int param) {
...
}
}
/** src/test/java/MyUseCaseTest.java */
class MyUseCaseTest {
private MyUseCase myUseCase;
@Before
public void initialize() {
myUseCase = new MyDefaultUseCaseFactory().createMyUseCase();
}
@Test
public void func1Test() {
assertEquals(/* expected */, myUseCase.func1(...));
assertEquals(/* expected */, myUseCase.func1(...));
...
}
@Test
public void func2Test() {
assertEquals(/* expected */, myUseCase.func2(...));
assertEquals(/* expected */, myUseCase.func2(...));
...
}
...
}
Code Coverage vs. Use-Case Coverage
Another popular practice is code coverage. In some companies there is a code coverage check as a part of the build pipeline and a commit is rejected if its code coverage is less than a particular percentage. Code coverage is a wrong metric - you can have 100% code coverage without actually to test anything.
Much more important is use-case coverage, telling us how much of our requirements are covered with test. We should always try to achive 100% use-case coverage, because satisfaction of use-cases determine the product quality.
Test Categories
We distinguish several test categories based on the level of granularity the test operates on.
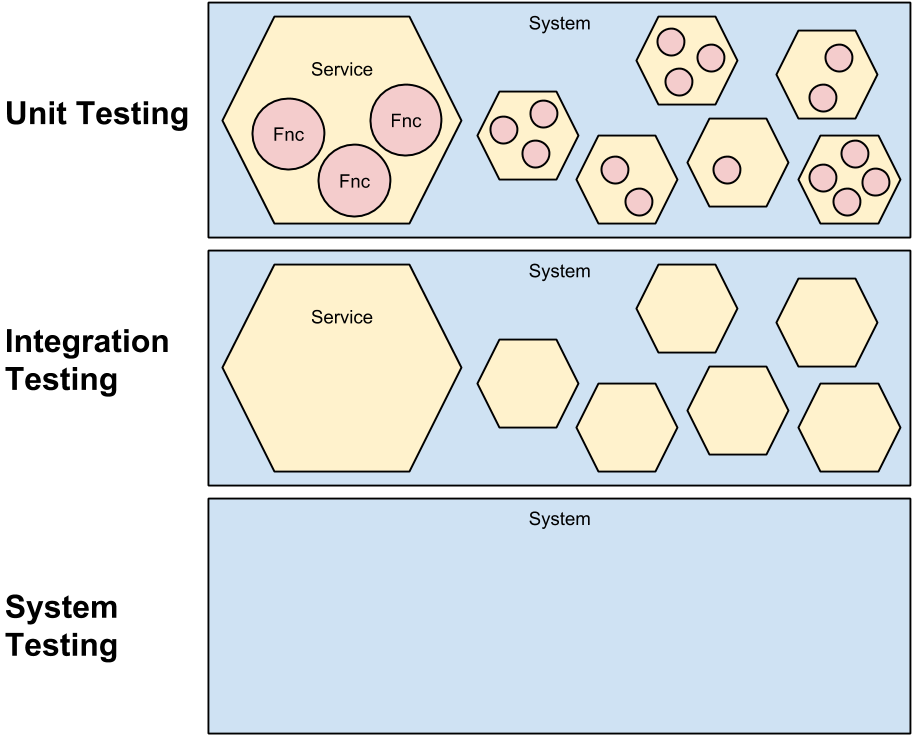
As showned in the picture, the unit testing operates on the level of functions, it can access the functionality of the smallest components via their APIs defined by public methods or exported function. Integration testing sees a service as a black box as well as system testing* has no idea about the services structure hidden behind the system's facade (gateway).
Unit Testing
Unit tests operate on the level of functions and should test only business functionality. If there is no business logic and a requirement is implemented only with composition of another resources (like saving into a database or calling another function/service) there's no reason for a unit test and the testing should be done as a part of integration testing (otherwise we write unit test as integrations test where all resources are mocked - such tests have no value).
To make unit testing possible we should always follow the Single Responsibility Principle by writting our code. If more responsibilities are mixed into one component, for example when a function transforms the input and saves it into a database, there is no other way how to test the transformation function but to mock the database. If we need a mock an dependency to be able to test our business logic in separation, the code probably needs refactoring.
Another thing which makes writting tests much easier is to avoid side-effects. A function with side-effects cannot be easily tested as a black box with inputs and outputs (both can be absent) and need a knowledge about its interns resp. implementation details. Use pure functions as much as possible.
Integration Testing
Integration Testing operates on the level of services, it means autonomous components, and tests their interactions.
Integration tests must run in the system environment so all the needed resources are available (and we don't have to mock anything).
Integration tests as well as unit tests belong to a service and should access only the service's API. If a test needs to access more services we call it a system test and it should run accross services (e.g. in a separate testing pipeline).
System Testing
System testing sees the entire system as a black box with a facase (gateway) API. Whole scenarios accross services are under the test.
Mocking is a Code Smell
If you follow the principles above you don't need to mock anything in your tests. If you can't test without mocking there must be something "smelly" in the design.
Of course, there could be exceptions like when a resource is too expensive or slow, but we should avoid mocking as much as possible, because it always removes a value from the tests.
Mocks are coupled to the implementation which makes them brittle. If you really have to mock out an expensive dependency, consider to use a fake object (simple implementations with business behavior) instead. Fake objects, in contrast to mocks, contain domain logic and are a part of the domain. Read more about test doubles and mocks vs. stubs to understand the difference.
Example: Money
Do you remember the Money example from Kent Beck's Test-Driven Development By Example? Let's use it as a base for our simple Money microservices system implemented with AWS.
The Money service offers an API for multiplication of money amounts and reduction into different currencies. The Exchange service provides information about the actual rate; we can implement it for example as pulling the data from the New York Stock Exchange via its API.
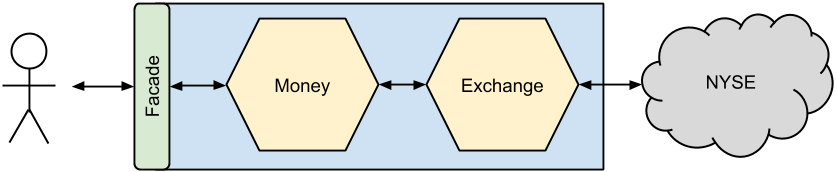
The source code could be found on GitHub. The implementation is far from perfect, but the idea is clear. Handlers (index.js) are separeted from the business (money.js and exchange.js), unit tests focus on the business, integration tests on handlers (which make APIs of the services) and system tests on the facade.
Each tests have a different place in the build pipeline. Unit tests are executed for every function, integration tests for every service (a bunch of functions) and system tests for the entire system (a bunch of services).
In our example there is only one function per service, but in a real-world scenario there would be much more. We can even think of a function per use-case. In such a case we would have two function in the Money service: times function and reduce function.
Happy testing!
*) System testing belongs together with GUI and manual testing into the group End-to-end testing which all operate on the same level of granularity. By system testing is in this article meant automatic testing of back-end functionality e.g. via system's REST API.